
README_en.md 24 KB
English | 简体中文
PP-PicoDet

News
- Released a new series of PP-PicoDet models: (2022.03.20)
- (1) It was used TAL/ETA Head and optimized PAN, which greatly improved the accuracy;
- (2) Moreover optimized CPU prediction speed, and the training speed is greatly improved;
- (3) The export model includes post-processing, and the prediction directly outputs the result, without secondary development, and the migration cost is lower.
Legacy Model
- Please refer to: PicoDet 2021.10
Introduction
We developed a series of lightweight models, named PP-PicoDet. Because of the excellent performance, our models are very suitable for deployment on mobile or CPU. For more details, please refer to our report on arXiv.
- 🌟 Higher mAP: the first object detectors that surpass mAP(0.5:0.95) 30+ within 1M parameters when the input size is 416.
- 🚀 Faster latency: 150FPS on mobile ARM CPU.
- 😊 Deploy friendly: support PaddleLite/MNN/NCNN/OpenVINO and provide C++/Python/Android implementation.
- 😍 Advanced algorithm: use the most advanced algorithms and offer innovation, such as ESNet, CSP-PAN, SimOTA with VFL, etc.

Benchmark
| Model | Input size | mAPval 0.5:0.95 | mAPval 0.5 | Params (M) | FLOPS (G) | LatencyCPU (ms) LatencyLite |
(ms) Weight |
Config |
Inference Model |
PicoDet-XS |
320*320 |
23.5 |
36.1 |
0.70 |
0.67 |
3.9ms |
7.81ms |
model | log |
config |
w/ postprocess | w/o postprocess |
PicoDet-XS |
416*416 |
26.2 |
39.3 |
0.70 |
1.13 |
6.1ms |
12.38ms |
model | log |
config |
w/ postprocess | w/o postprocess |
PicoDet-S |
320*320 |
29.1 |
43.4 |
1.18 |
0.97 |
4.8ms |
9.56ms |
model | log |
config |
w/ postprocess | w/o postprocess |
PicoDet-S |
416*416 |
32.5 |
47.6 |
1.18 |
1.65 |
6.6ms |
15.20ms |
model | log |
config |
w/ postprocess | w/o postprocess |
PicoDet-M |
320*320 |
34.4 |
50.0 |
3.46 |
2.57 |
8.2ms |
17.68ms |
model | log |
config |
w/ postprocess | w/o postprocess |
PicoDet-M |
416*416 |
37.5 |
53.4 |
3.46 |
4.34 |
12.7ms |
28.39ms |
model | log |
config |
w/ postprocess | w/o postprocess |
PicoDet-L |
320*320 |
36.1 |
52.0 |
5.80 |
4.20 |
11.5ms |
25.21ms |
model | log |
config |
w/ postprocess | w/o postprocess |
PicoDet-L |
416*416 |
39.4 |
55.7 |
5.80 |
7.10 |
20.7ms |
42.23ms |
model | log |
config |
w/ postprocess | w/o postprocess |
PicoDet-L |
640*640 |
42.6 |
59.2 |
5.80 |
16.81 |
62.5ms |
108.1ms |
model | log |
config |
w/ postprocess | w/o postprocess |
|
|---|
| Model | Input size | mAPval 0.5:0.95 | mAPval 0.5 | Params (M) | FLOPS (G) | LatencyNCNN (ms) |
|---|---|---|---|---|---|---|
| YOLOv3-Tiny | 416*416 | 16.6 | 33.1 | 8.86 | 5.62 | 25.42 |
| YOLOv4-Tiny | 416*416 | 21.7 | 40.2 | 6.06 | 6.96 | 23.69 |
| PP-YOLO-Tiny | 320*320 | 20.6 | - | 1.08 | 0.58 | 6.75 |
| PP-YOLO-Tiny | 416*416 | 22.7 | - | 1.08 | 1.02 | 10.48 |
| Nanodet-M | 320*320 | 20.6 | - | 0.95 | 0.72 | 8.71 |
| Nanodet-M | 416*416 | 23.5 | - | 0.95 | 1.2 | 13.35 |
| Nanodet-M 1.5x | 416*416 | 26.8 | - | 2.08 | 2.42 | 15.83 |
| YOLOX-Nano | 416*416 | 25.8 | - | 0.91 | 1.08 | 19.23 |
| YOLOX-Tiny | 416*416 | 32.8 | - | 5.06 | 6.45 | 32.77 |
| YOLOv5n | 640*640 | 28.4 | 46.0 | 1.9 | 4.5 | 40.35 |
| YOLOv5s | 640*640 | 37.2 | 56.0 | 7.2 | 16.5 | 78.05 |
| Model | Input size | ONNX(w/o postprocess) | Paddle Lite(fp32) | Paddle Lite(fp16) |
|---|---|---|---|---|
| PicoDet-XS | 320*320 | ( w/ postprocess) | ( w/o postprocess) | model | model |
| PicoDet-XS | 416*416 | ( w/ postprocess) | ( w/o postprocess) | model | model |
| PicoDet-S | 320*320 | ( w/ postprocess) | ( w/o postprocess) | model | model |
| PicoDet-S | 416*416 | ( w/ postprocess) | ( w/o postprocess) | model | model |
| PicoDet-M | 320*320 | ( w/ postprocess) | ( w/o postprocess) | model | model |
| PicoDet-M | 416*416 | ( w/ postprocess) | ( w/o postprocess) | model | model |
| PicoDet-L | 320*320 | ( w/ postprocess) | ( w/o postprocess) | model | model |
| PicoDet-L | 416*416 | ( w/ postprocess) | ( w/o postprocess) | model | model |
| PicoDet-L | 640*640 | ( w/ postprocess) | ( w/o postprocess) model | model |
Deploy
| Infer Engine | Python | C++ | Predict With Postprocess |
|---|---|---|---|
| OpenVINO | Python | C++(postprocess coming soon) | ✔︎ |
| Paddle Lite | - | C++ | ✔︎ |
| Android Demo | - | Paddle Lite | ✔︎ |
| PaddleInference | Python | C++ | ✔︎ |
| ONNXRuntime | Python | Coming soon | ✔︎ |
| NCNN | Coming soon | C++ | ✘ |
| MNN | Coming soon | C++ | ✘ |
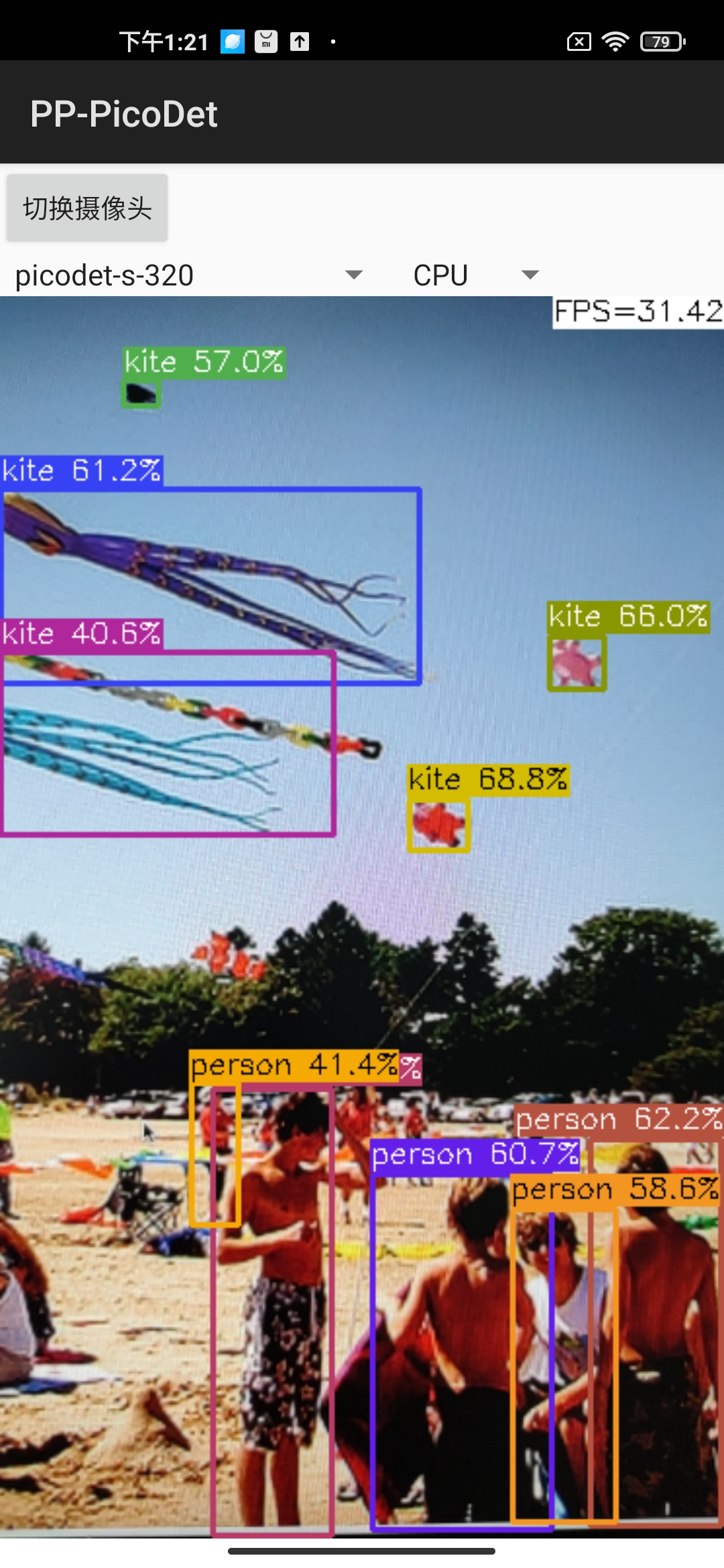
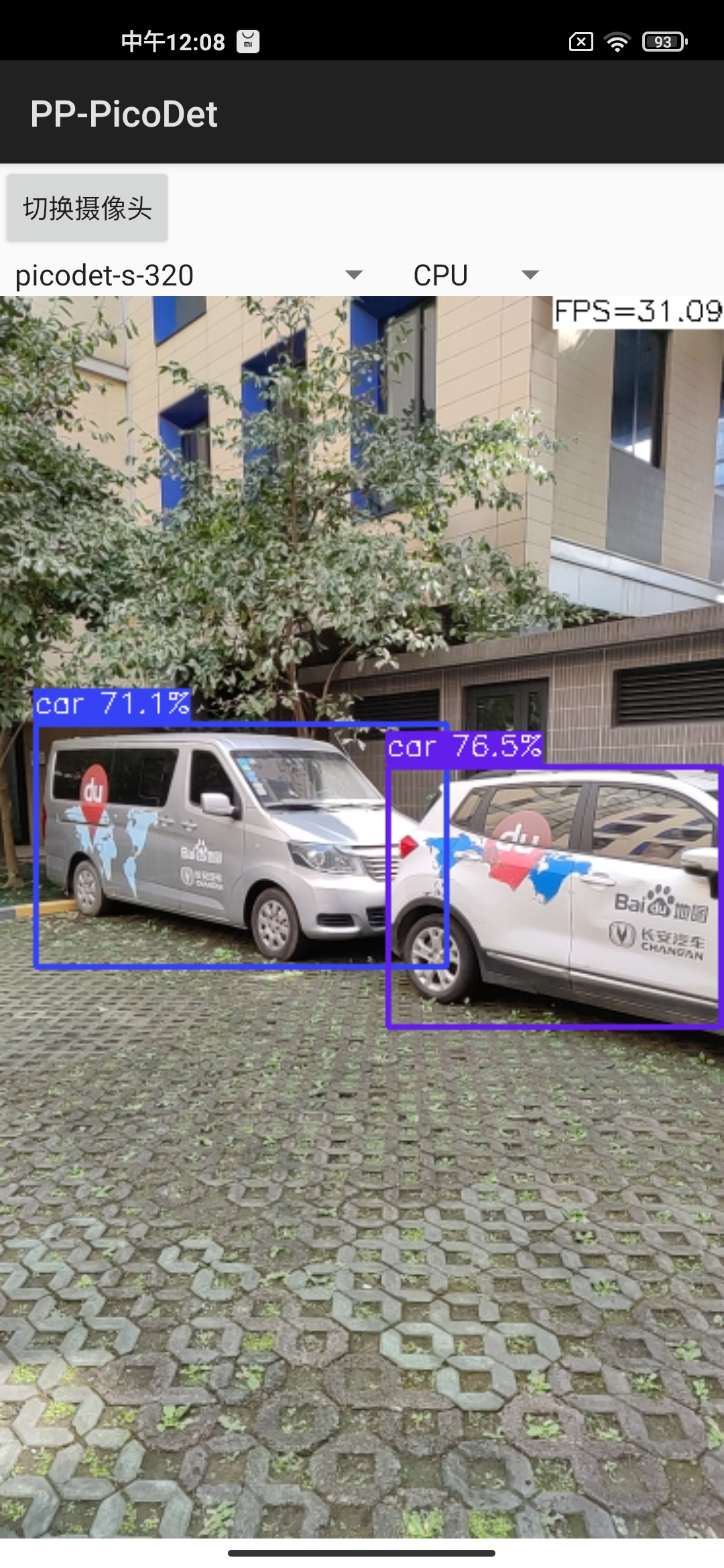
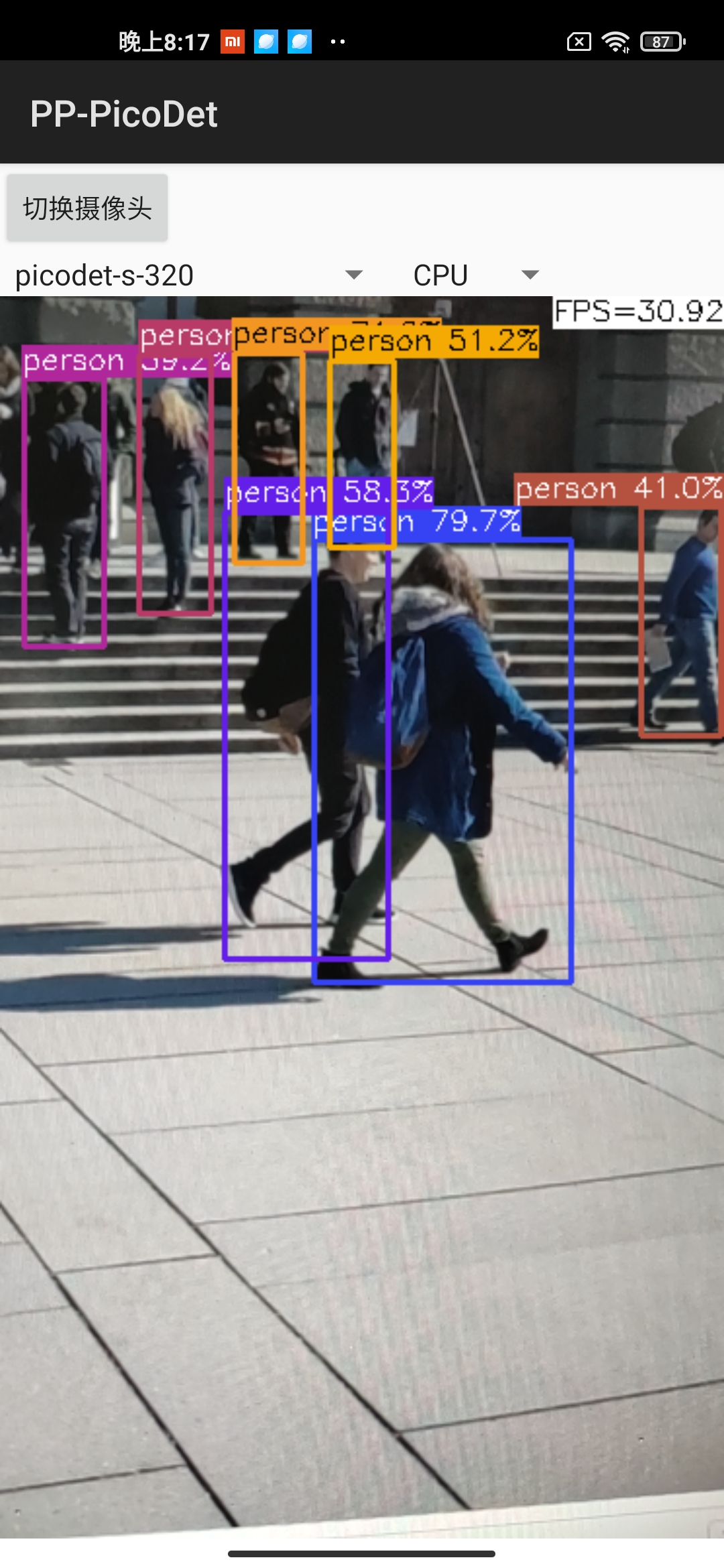
Android demo visualization:

Quantization
Requirements:
- PaddlePaddle >= 2.2.2
- PaddleSlim >= 2.2.2
Install:
pip install paddleslim==2.2.2
Quant aware
Configure the quant config and start training:
python tools/train.py -c configs/picodet/picodet_s_416_coco_lcnet.yml \
--slim_config configs/slim/quant/picodet_s_416_lcnet_quant.yml --eval
- More detail can refer to slim document
- Quant Aware Model ZOO:
| Quant Model | Input size | mAPval 0.5:0.95 | Configs | Weight | Inference Model | Paddle Lite(INT8) |
|---|---|---|---|---|---|---|
| PicoDet-S | 416*416 | 31.5 | config | slim config | model | w/ postprocess | w/o postprocess | w/ postprocess | w/o postprocess |