
ppocr_introduction.md 9.5 KB
English | 简体中文
PP-OCR
1. 简介
PP-OCR是PaddleOCR自研的实用的超轻量OCR系统。在实现前沿算法的基础上,考虑精度与速度的平衡,进行模型瘦身和深度优化,使其尽可能满足产业落地需求。
PP-OCR
PP-OCR是一个两阶段的OCR系统,其中文本检测算法选用DB,文本识别算法选用CRNN,并在检测和识别模块之间添加文本方向分类器,以应对不同方向的文本识别。
PP-OCR系统pipeline如下:
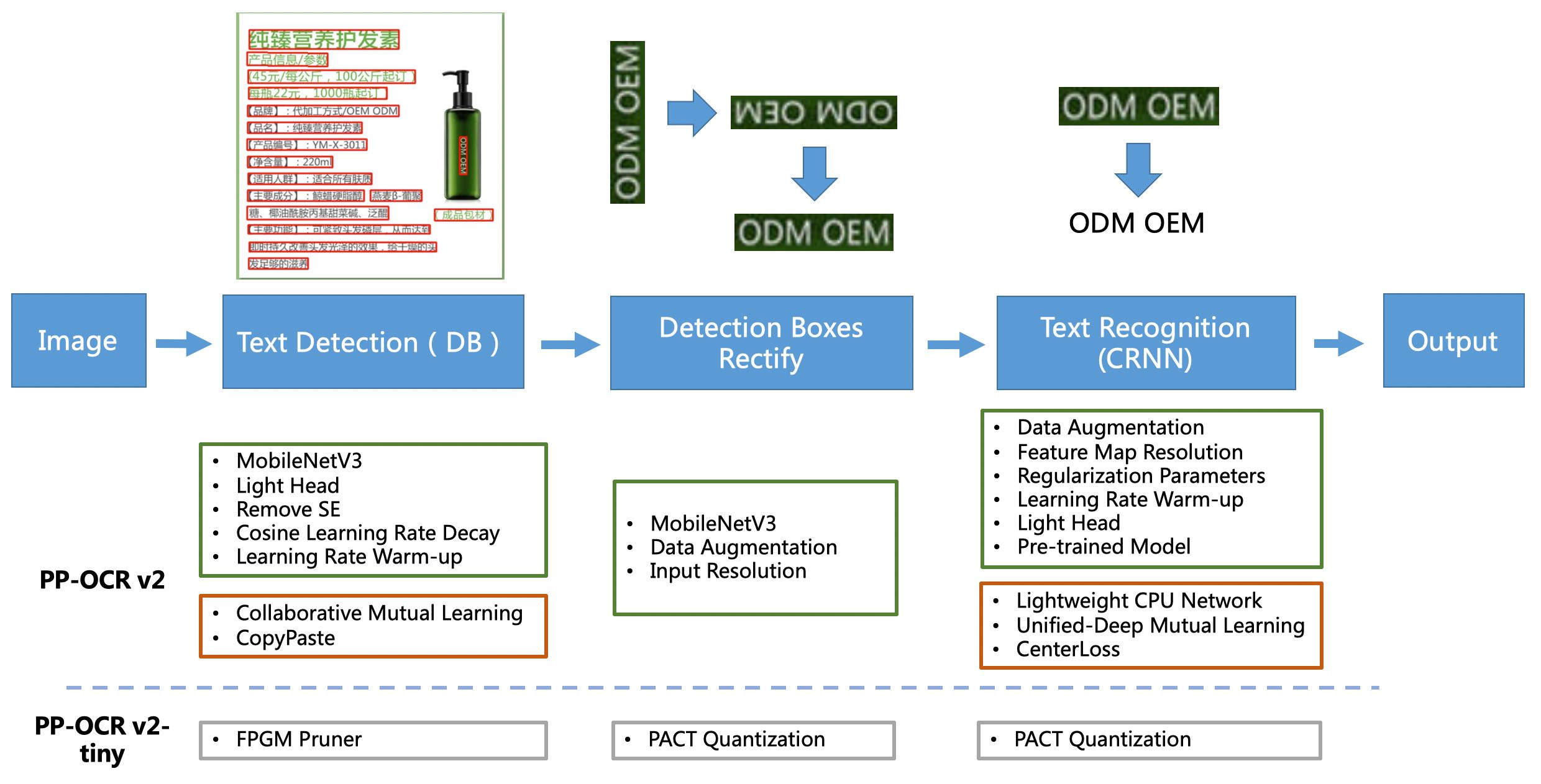
PP-OCR系统在持续迭代优化,目前已发布PP-OCR和PP-OCRv2两个版本:
PP-OCR从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身(如绿框所示),最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。更多细节请参考PP-OCR技术报告。
PP-OCRv2
PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和Enhanced CTC loss损失函数改进(如上图红框所示),进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2技术报告。
PP-OCRv3
PP-OCRv3在PP-OCRv2的基础上,针对检测模型和识别模型,进行了共计9个方面的升级:
- PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
- PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
PP-OCRv3系统pipeline如下:
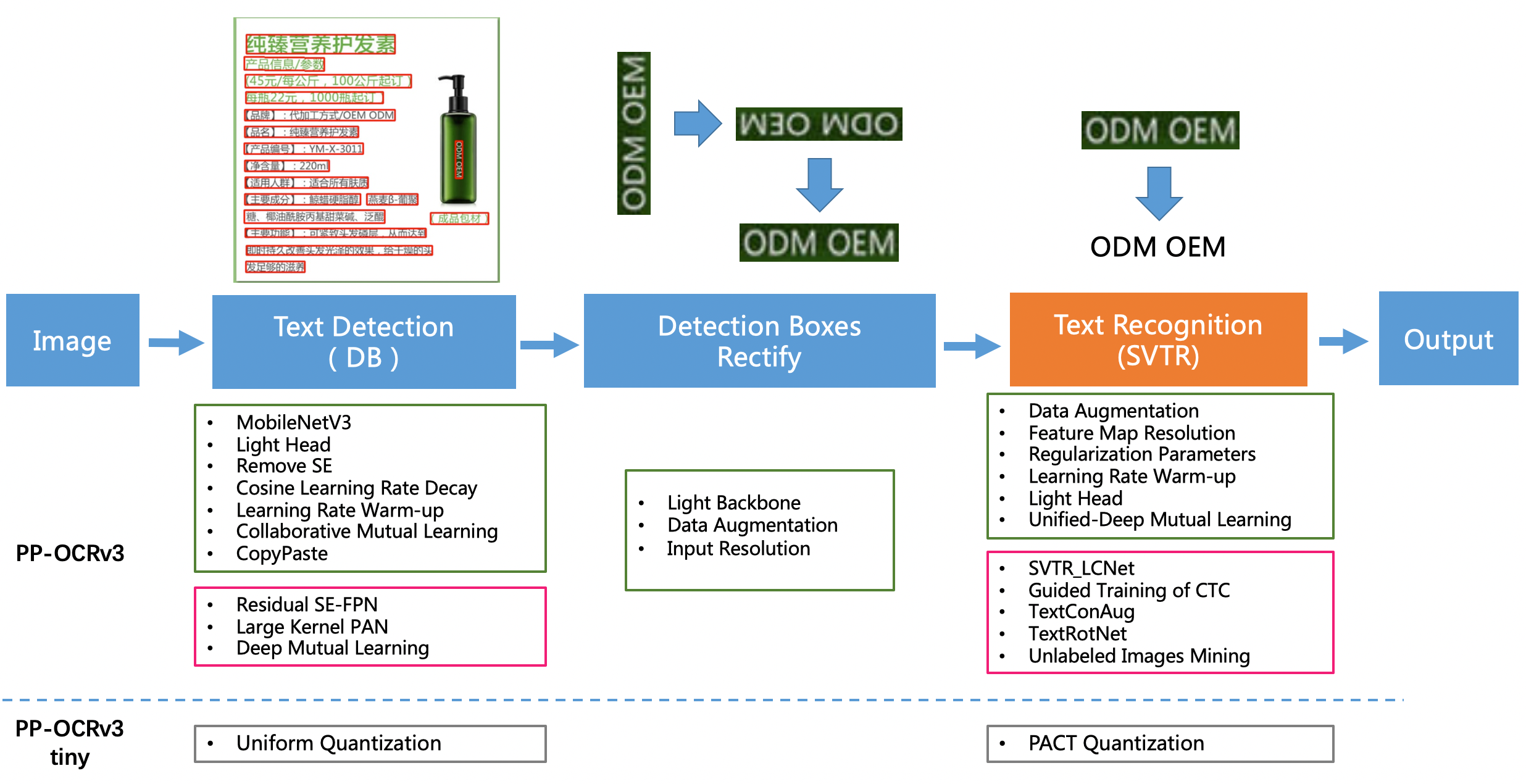
更多细节请参考PP-OCRv3技术报告 👉中文简洁版
2. 特性
- 超轻量PP-OCRv3系列:检测(3.6M)+ 方向分类器(1.4M)+ 识别(12M)= 17.0M
- 超轻量PP-OCRv2系列:检测(3.1M)+ 方向分类器(1.4M)+ 识别(8.5M)= 13.0M
- 超轻量PP-OCR mobile移动端系列:检测(3.0M)+方向分类器(1.4M)+ 识别(5.0M)= 9.4M
- 通用PP-OCR server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
- 支持中英文数字组合识别、竖排文本识别、长文本识别
- 支持多语言识别:韩语、日语、德语、法语等约80种语言
3. benchmark
关于PP-OCR系列模型之间的性能对比,请查看benchmark文档。
4. 效果展示 more
PP-OCRv3 中文模型
<img src="../imgs_results/PP-OCRv3/ch/PP-OCRv3-pic001.jpg" width="800">
<img src="../imgs_results/PP-OCRv3/ch/PP-OCRv3-pic002.jpg" width="800">
<img src="../imgs_results/PP-OCRv3/ch/PP-OCRv3-pic003.jpg" width="800">
PP-OCRv3 英文模型
<img src="../imgs_results/PP-OCRv3/en/en_1.png" width="800">
<img src="../imgs_results/PP-OCRv3/en/en_2.png" width="800">
PP-OCRv3 多语言模型
<img src="../imgs_results/PP-OCRv3/multi_lang/japan_2.jpg" width="800">
<img src="../imgs_results/PP-OCRv3/multi_lang/korean_1.jpg" width="800">
5. 使用教程
5.1 快速体验
- 在线网站体验:超轻量PP-OCR mobile模型体验地址:https://www.paddlepaddle.org.cn/hub/scene/ocr
- 移动端demo体验:安装包DEMO下载地址(基于EasyEdge和Paddle-Lite, 支持iOS和Android系统)
- 一行命令快速使用:快速开始(中英文/多语言)
5.2 模型训练、压缩、推理部署
更多教程,包括模型训练、模型压缩、推理部署等,请参考文档教程。
6. 模型库
PP-OCR中英文模型列表如下:
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|---|---|---|---|---|---|
| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 |
| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 |
更多模型下载(包括英文数字模型、多语言模型、Paddle-Lite模型等),可以参考PP-OCR 系列模型下载。