
 yangjun
b0c1878a97
初始化PaddleOCR
yangjun
b0c1878a97
初始化PaddleOCR
|
1 rok pred | |
|---|---|---|
| .. | ||
| arch | 1 rok pred | |
| configs | 1 rok pred | |
| doc | 1 rok pred | |
| engine | 1 rok pred | |
| examples | 1 rok pred | |
| fonts | 1 rok pred | |
| tools | 1 rok pred | |
| utils | 1 rok pred | |
| README.md | 1 rok pred | |
| README_ch.md | 1 rok pred | |
| __init__.py | 1 rok pred | |
README.md
English | 简体中文
Style Text
Contents
Introduction
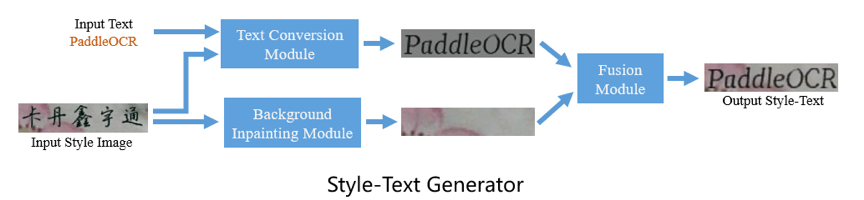

The Style-Text data synthesis tool is a tool based on Baidu and HUST cooperation research work, "Editing Text in the Wild" https://arxiv.org/abs/1908.03047.
Different from the commonly used GAN-based data synthesis tools, the main framework of Style-Text includes:
- (1) Text foreground style transfer module.
- (2) Background extraction module.
- (3) Fusion module.
After these three steps, you can quickly realize the image text style transfer. The following figure is some results of the data synthesis tool.

Preparation
- Please refer the QUICK INSTALLATION to install PaddlePaddle. Python3 environment is strongly recommended.
- Download the pretrained models and unzip:
cd StyleText
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/style_text/style_text_models.zip
unzip style_text_models.zip
If you save the model in another location, please modify the address of the model file in configs/config.yml, and you need to modify these three configurations at the same time:
bg_generator:
pretrain: style_text_models/bg_generator
...
text_generator:
pretrain: style_text_models/text_generator
...
fusion_generator:
pretrain: style_text_models/fusion_generator
Quick Start
Synthesis single image
- You can run
tools/synth_imageand generate the demo image, which is saved in the current folder.
python3 tools/synth_image.py -c configs/config.yml --style_image examples/style_images/2.jpg --text_corpus PaddleOCR --language en
- Note 1: The language options is correspond to the corpus. Currently, the tool only supports English(en), Simplified Chinese(ch) and Korean(ko).
- Note 2: Synth-Text is mainly used to generate images for OCR recognition models. So the height of style images should be around 32 pixels. Images in other sizes may behave poorly.
- Note 3: You can modify
use_gpuinconfigs/config.ymlto determine whether to use GPU for prediction.
For example, enter the following image and corpus PaddleOCR.

The result fake_fusion.jpg will be generated.
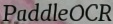
What's more, the medium result fake_bg.jpg will also be saved, which is the background output.

fake_text.jpg * fake_text.jpg is the generated image with the same font style as Style Input.
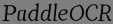
Batch synthesis
In actual application scenarios, it is often necessary to synthesize pictures in batches and add them to the training set. StyleText can use a batch of style pictures and corpus to synthesize data in batches. The synthesis process is as follows:
The referenced dataset can be specifed in
configs/dataset_config.yml:Global:output_dir::Output synthesis data path.
StyleSampler:image_home:style images' folder.label_file:Style images' file list. If label is provided, then it is the label file path.with_label:Whether thelabel_fileis label file list.
CorpusGenerator:method:Method of CorpusGenerator,supportsFileCorpusandEnNumCorpus. IfEnNumCorpusis used,No other configuration is needed,otherwise you need to setcorpus_fileandlanguage.language:Language of the corpus. Currently, the tool only supports English(en), Simplified Chinese(ch) and Korean(ko).corpus_file: Filepath of the corpus. Corpus file should be a text file which will be split by line-endings('\n'). Corpus generator samples one line each time.
Example of corpus file:
PaddleOCR
飞桨文字识别
StyleText
风格文本图像数据合成
We provide a general dataset containing Chinese, English and Korean (50,000 images in all) for your trial (download link), some examples are given below :

- You can run the following command to start synthesis task:
python3 tools/synth_dataset.py -c configs/dataset_config.yml
We also provide example corpus and images in examples folder.
<div align="center">
<img src="examples/style_images/1.jpg" width="300">
<img src="examples/style_images/2.jpg" width="300">
</div>
If you run the code above directly, you will get example output data in output_data folder.
You will get synthesis images and labels as below:
<img src="doc/images/12.png" width="800">
label folder. If the program exit unexpectedly, you can find cached labels there.
When the program finish normally, you will find all the labels in label.txt which give the final results.
Applications
We take two scenes as examples, which are metal surface English number recognition and general Korean recognition, to illustrate practical cases of using StyleText to synthesize data to improve text recognition. The following figure shows some examples of real scene images and composite images:

After adding the above synthetic data for training, the accuracy of the recognition model is improved, which is shown in the following table:
| Scenario | Characters | Raw Data | Test Data | Only Use Raw Data | Recognition AccuracyNew Synthetic Data | Simultaneous Use of Synthetic Data | Recognition AccuracyIndex Improvement |
|---|
Code Structure
StyleText
|-- arch // Network module files.
| |-- base_module.py
| |-- decoder.py
| |-- encoder.py
| |-- spectral_norm.py
| `-- style_text_rec.py
|-- configs // Config files.
| |-- config.yml
| `-- dataset_config.yml
|-- engine // Synthesis engines.
| |-- corpus_generators.py // Sample corpus from file or generate random corpus.
| |-- predictors.py // Predict using network.
| |-- style_samplers.py // Sample style images.
| |-- synthesisers.py // Manage other engines to synthesis images.
| |-- text_drawers.py // Generate standard input text images.
| `-- writers.py // Write synthesis images and labels into files.
|-- examples // Example files.
| |-- corpus
| | `-- example.txt
| |-- image_list.txt
| `-- style_images
| |-- 1.jpg
| `-- 2.jpg
|-- fonts // Font files.
| |-- ch_standard.ttf
| |-- en_standard.ttf
| `-- ko_standard.ttf
|-- tools // Program entrance.
| |-- __init__.py
| |-- synth_dataset.py // Synthesis dataset.
| `-- synth_image.py // Synthesis image.
`-- utils // Module of basic functions.
|-- config.py
|-- load_params.py
|-- logging.py
|-- math_functions.py
`-- sys_funcs.py