
浏览代码
第一次上传

+ 32
- 0
Images_rename/images_rename.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 0
TextRecognitionDataGenerator
|
||
|
||
+ 56
- 0
classification_dataset_generate/divide_train_eval.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
二进制
correct_imgs_rotation/correted_imgs/16602752667386.png
{kind=link}
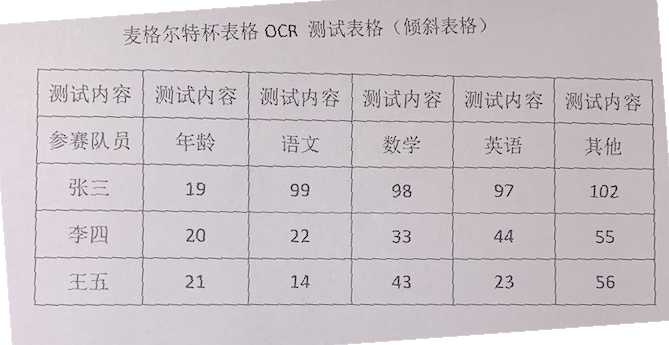
+ 50
- 0
correct_imgs_rotation/img_correct.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
二进制
correct_imgs_rotation/imgs/16602752667386.png
{kind=link}
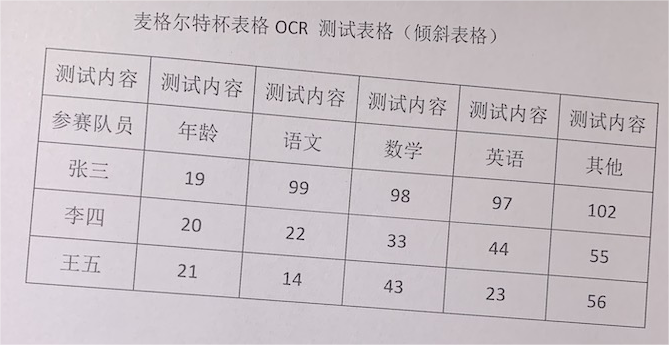
二进制
correct_imgs_rotation/result/16602752667386.png
{kind=link}
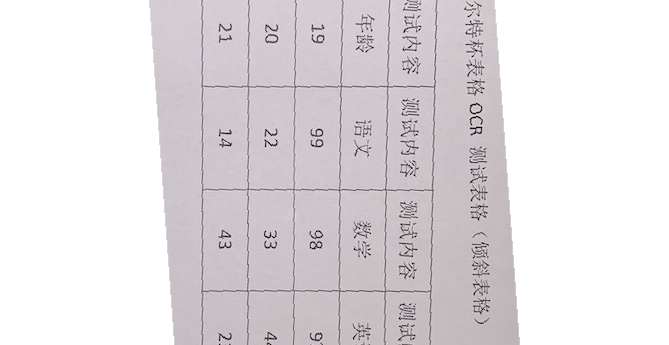
+ 41
- 0
delete_anno_by_label/delete_label.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 15
- 0
dictionary_generate/chn_text.txt
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
文件差异内容过多而无法显示
+ 1
- 0
dictionary_generate/dict_chn_2000.txt
文件差异内容过多而无法显示
+ 1
- 0
dictionary_generate/dict_chn_3500.txt
文件差异内容过多而无法显示
+ 8763
- 0
dictionary_generate/dict_eng_8763.txt
文件差异内容过多而无法显示
+ 4320
- 0
dictionary_generate/eng_text.txt
+ 36
- 0
dictionary_generate/generate.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 36
- 0
dictionary_generate/test.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 3
- 0
divide_and_convert_to_coco_single_fold/.idea/.gitignore
|
||
|
||
|
||
|
||
+ 8
- 0
divide_and_convert_to_coco_single_fold/.idea/3、数据集划分训练集验证集、转coco格式.iml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 26
- 0
divide_and_convert_to_coco_single_fold/.idea/inspectionProfiles/Project_Default.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 6
- 0
divide_and_convert_to_coco_single_fold/.idea/inspectionProfiles/profiles_settings.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 4
- 0
divide_and_convert_to_coco_single_fold/.idea/misc.xml
|
||
|
||
|
||
|
||
|
||
+ 8
- 0
divide_and_convert_to_coco_single_fold/.idea/modules.xml
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 160
- 0
divide_and_convert_to_coco_single_fold/labelme_to_coco.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
二进制
fonts_images_generate/__pycache__/img_tools.cpython-37.pyc
+ 56
- 0
fonts_images_generate/divide_train_eval.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
二进制
fonts_images_generate/font/Apple Braille.ttf
+ 63
- 0
fonts_images_generate/generate_imgs_by_fonts.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 24
- 0
fonts_images_generate/get_all_labels.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 31
- 0
fonts_images_generate/gray.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0000_ffec5264.jpg
{kind=link}
二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0001_fff5a1cc.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0002_fffd428a.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0003_00053198.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0004_000d6f00.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0005_00151406.jpg
{kind=link}
二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0006_001d0300.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0007_0024a1ee.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0008_002c1b36.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0009_00339894.jpg
{kind=link}
二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0010_003a7642.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0011_0041544c.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0012_0047dfec.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0013_004e9742.jpg
{kind=link}

二进制
fonts_images_generate/images/PingFang/kdan_2022-10-25_0014_00555134.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0000_00b5c174.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0001_00ba9f66.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0002_00bf80e8.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0003_00c54d66.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0004_00ca7dee.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0005_00cf8668.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0006_00d4ba3e.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0007_00d9c15a.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0008_00de7eb0.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0009_00e36088.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0010_00e7f466.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0011_00ecd668.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0012_00f20290.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0013_00f70c2e.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Light/kdan_2022-10-25_0014_00fbee28.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0000_010144c8.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0001_01064e66.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0002_010b7e02.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0003_0110ae14.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0004_0116054c.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0005_011b0e52.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0006_012128dc.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0007_01265900.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0008_012b6290.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0009_01306ba8.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0010_013574ee.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0011_013a7dca.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0012_013fad64.jpg
{kind=link}

二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0013_01448f62.jpg
{kind=link}
二进制
fonts_images_generate/images/STHeiti Medium/kdan_2022-10-25_0014_0149986c.jpg
{kind=link}

二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0000_005c79d8.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0001_00627094.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0002_006815f4.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0003_006e7aa8.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0004_00750e7e.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0005_007b2598.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0006_0081910a.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0007_00875db8.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0008_008d26c6.jpg
{kind=link}

二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0009_00931de2.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0010_0098ea08.jpg
{kind=link}

二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0011_009edd3a.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0012_00a4cd40.jpg
{kind=link}
二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0013_00aac0e6.jpg
{kind=link}

二进制
fonts_images_generate/images/Songti/kdan_2022-10-25_0014_00b08d5a.jpg
{kind=link}

+ 5
- 0
fonts_images_generate/images/label_list.txt
|
||
|
||
|
||
|
||
|
||
|
||
+ 15
- 0
fonts_images_generate/img_paddling.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 22
- 0
fonts_images_generate/img_tools.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
文件差异内容过多而无法显示
+ 7560
- 0
fonts_images_generate/text/chn_text.txt
+ 14
- 0
fonts_images_generate/text/chn_text_test.txt
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
文件差异内容过多而无法显示
+ 2160
- 0
fonts_images_generate/text/eng_text.txt
+ 15
- 0
fonts_images_generate/text/eng_text_test.txt
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
文件差异内容过多而无法显示
+ 114494
- 0
get_name_by_spider/addr.txt
+ 9
- 0
get_name_by_spider/get_dict.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 22
- 0
get_name_by_spider/get_name.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||